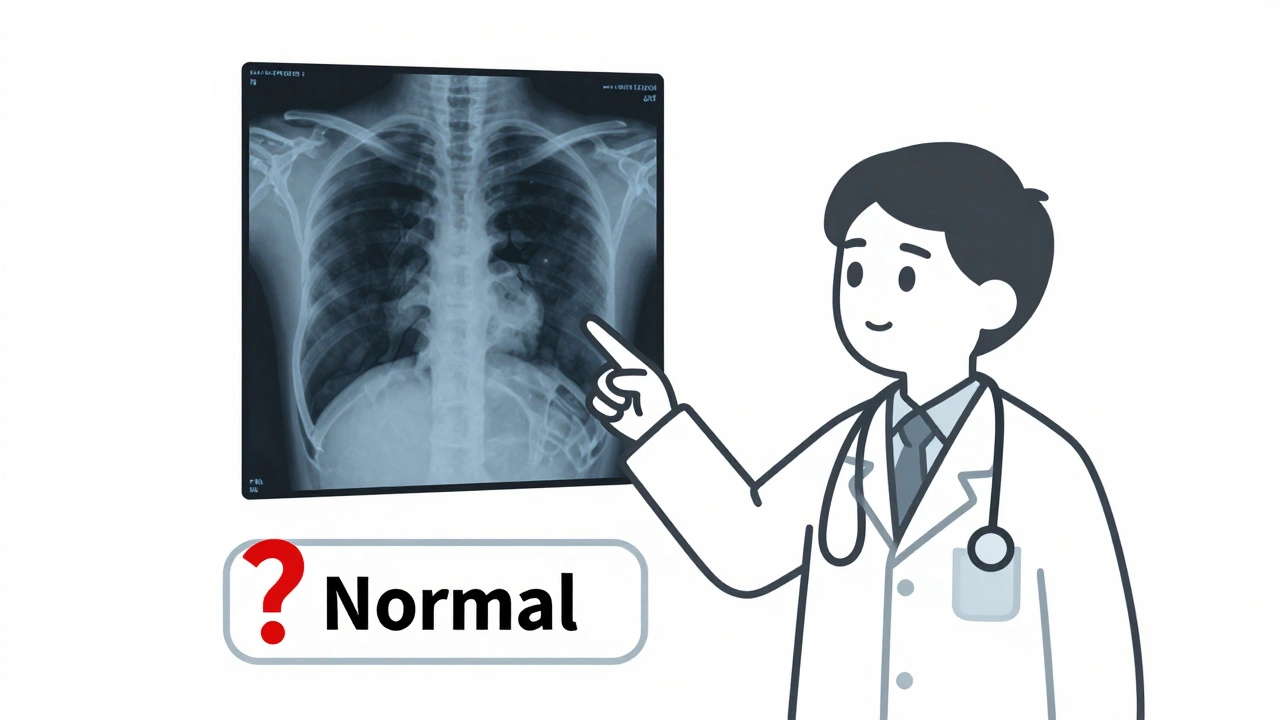
When you're working with medical data - like patient records, drug labels, or diagnostic images - a single wrong label can mean the difference between a correct diagnosis and a dangerous mistake. Labeling errors in datasets used to train AI models for healthcare aren’t just technical glitches. They’re patient safety risks. If a radiology image is mislabeled as "normal" when it shows a tumor, or a drug name is tagged as "ibuprofen" instead of "ibuprofen 800mg," the AI learns the wrong thing. And it will keep making that mistake, over and over.
What Labeling Errors Look Like in Medical Data
Labeling errors don’t always jump out. They’re often subtle, but their impact is huge. In medical datasets, these errors fall into clear patterns:- Missing labels: An abnormality in an X-ray isn’t marked at all. This happens in 32% of object detection errors in medical imaging, according to Label Studio’s 2022 analysis.
- Wrong boundaries: A tumor is labeled, but the box drawn around it cuts off part of the lesion. This accounts for 41% of entity recognition errors in clinical text.
- Incorrect classification: A drug is labeled as "antibiotic" when it’s actually an antiviral. Misclassified entity types make up 33% of errors in medication datasets.
- Ambiguous or out-of-distribution examples: A note says "patient reports dizziness after taking med" - but the label says "adverse reaction" when the drug isn’t even in the approved list. These confuse models and account for 15-25% of text classification errors.
- Midstream tag changes: The team changes the label from "hypertension" to "high blood pressure" halfway through the project. Without version control, the dataset becomes a mess.
These aren’t random mistakes. They come from unclear instructions, rushed annotation, or lack of domain expertise. A 2022 study by TEKLYNX found that 68% of labeling errors in industrial and medical projects stemmed directly from vague or incomplete guidelines.
How to Spot Them - Even Without Coding
You don’t need to be a data scientist to find these errors. Here’s how to do it manually, using tools you already have access to:- Compare annotations side by side. Open two or three different annotators’ work on the same image or text. If one says "aspirin 81mg" and another says "aspirin," that’s a red flag. Disagreements mean inconsistency - and likely error.
- Look for outliers. If 98% of the labels for a drug are "metformin," but one entry says "metformin 1000mg" while the rest are 500mg, check if that’s a typo or a valid variation. Unusual patterns often point to mistakes.
- Use model predictions as a filter. If you’re using a tool like Datasaur or Argilla, run the dataset through a trained model. It will flag entries where the model is uncertain. These are your high-risk candidates. Even if the model isn’t perfect, its uncertainty tells you where to look.
- Read the raw data aloud. For text labels, reading out loud helps catch mismatched terms. If the text says "patient allergic to penicillin" but the label is "no allergies," you’ve found an error.
Tools like cleanlab can automate this, but they require technical setup. For most teams working in pharmacy or clinical settings, manual spot-checking with these methods is faster, cheaper, and just as effective - especially when combined with peer review.

How to Ask for Corrections - Without Burning Bridges
Finding an error is only half the battle. Getting it fixed requires clear, respectful communication. Here’s how to do it:- Don’t say "you made a mistake." Say: "I noticed this label might need a second look. Can we check the source document?"
- Include the evidence. Attach the original image, text snippet, or reference guideline. Example: "The patient’s chart says ‘ibuprofen 400mg,’ but the label says ‘ibuprofen 200mg.’ Could we verify?"
- Use a shared tracking system. Tools like Label Studio or Argilla let you flag items with comments. Use them. Don’t send a Slack message - log it in the system so it’s traceable and doesn’t get lost.
- Offer a correction, not just a complaint. Instead of just saying "this is wrong," suggest: "I think this should be labeled ‘anticoagulant’ based on the prescribing note. Can we confirm?"
People make errors because they’re tired, rushed, or unsure. Your job isn’t to blame - it’s to improve the system. Teams that use this approach see 50% faster correction turnaround and higher annotator retention.
Preventing Errors Before They Happen
The best way to fix labeling errors is to stop them before they’re made:- Write clear labeling instructions. Include 3-5 real examples for every label. Don’t just say "label all drugs." Say: "Label all active pharmaceutical ingredients (e.g., metformin, lisinopril) - but not brand names like ‘Advil’ unless specified in guidelines."
- Use version-controlled guidelines. If you update the rules, document it. Name the version: "Labeling Guide v2.1 - Updated 12/1/2025."
- Run a pilot test. Have 3 annotators label 50 samples together. Review their results as a group. You’ll catch 80% of ambiguities before the full project starts.
- Train annotators on medical context. A person who doesn’t know the difference between "hypotension" and "hypertension" will mislabel 1 in 5 entries. Domain knowledge matters.
TEKLYNX’s 2022 study showed that teams using these practices reduced labeling errors by 47% in just two months.
Why This Matters More Than You Think
In healthcare, poor data quality doesn’t just slow down AI development - it endangers lives. A 2023 FDA guidance document explicitly requires that training datasets for AI medical devices include "systematic validation of labeling accuracy." If your dataset has 8% labeling errors - which is average - your AI model’s accuracy is capped at 92%, no matter how advanced it is. Professor Aleksander Madry from MIT put it bluntly: "No amount of model complexity can overcome bad labels."And it’s not just about accuracy. Regulatory bodies, insurers, and hospitals are starting to audit data quality. If you’re building a drug interaction checker or a medication alert system, your data pipeline will be scrutinized. Clean, verified labels aren’t a nice-to-have - they’re a compliance requirement.
What to Do Next
Start small. Pick one dataset - maybe your most critical one, like medication allergy labels or prescription transcription. Run a manual review using the methods above. Flag 10-20 errors. Correct them. Track how the model’s performance improves. You’ll see results fast.Then, build a simple checklist:
- Are labeling instructions clear and example-rich?
- Are annotators trained on medical terminology?
- Are multiple annotators reviewing high-risk items?
- Are corrections logged and tracked?
- Is there a process to update guidelines when new cases come up?
Do this once a month. You’ll turn labeling from a chaotic, error-prone task into a reliable, auditable process.
How common are labeling errors in medical datasets?
Labeling errors are extremely common. In medical datasets, error rates typically range from 5% to 15%, with some studies showing up to 20% in complex cases like radiology or clinical note annotation. A 2023 Encord report found medical imaging datasets average 8.2% label errors - higher than general computer vision tasks due to subtle visual differences and inconsistent terminology.
Can AI tools automatically fix labeling errors?
AI tools like cleanlab, Argilla, and Datasaur can flag likely errors with 70-90% accuracy, but they can’t fix them reliably without human input. These tools identify suspicious labels - for example, a drug labeled as "insulin" when the text says "glucagon" - but they don’t know the clinical context. A human must verify whether it’s a true error or a rare but valid case. Over-relying on automation can introduce new mistakes, especially with minority conditions or unusual drug combinations.
What’s the best tool for detecting labeling errors in medication data?
For teams without developers, Datasaur is the easiest to use - it integrates directly with annotation workflows and highlights inconsistencies in text-based medication labels. For teams with technical support, cleanlab offers the most statistically robust detection, especially for classification tasks. Argilla is ideal if you’re already using Hugging Face models or need a collaborative interface. But no tool replaces human review in healthcare - always combine automation with expert validation.
How long does it take to correct labeling errors in a dataset?
It depends on the size and complexity. For a dataset of 1,000 medication records, manual review and correction typically takes 4-8 hours with two annotators working together. Using automated tools like cleanlab can cut that time in half by narrowing down the list of likely errors. But the final validation - where a pharmacist or clinician confirms each correction - adds another 2-4 hours. Plan for at least one full workday per 1,000 samples.
Do labeling errors affect real-world patient outcomes?
Yes. A 2024 study from the University of Bristol found that AI systems trained on datasets with 10% labeling errors in drug interaction alerts produced false negatives - missing dangerous interactions - at a rate 3.5 times higher than systems trained on clean data. In one case, a model failed to flag a life-threatening interaction between warfarin and a newly prescribed antibiotic because the training data had mislabeled 12% of similar cases. This isn’t theoretical - it’s happening in clinics today.
How do I convince my team to prioritize label quality?
Show them the cost of getting it wrong. Compare model accuracy before and after fixing 50 labels. Track how many false alerts or missed warnings disappear. Use real examples: "This error caused the system to miss a critical interaction in 3 patients last month." Tie quality to safety, compliance, and trust. Most teams will act once they see that poor labels aren’t just a data issue - they’re a risk to patients and liability to the organization.


9 Comments
OMG YES THIS IS SO TRUE 😭 I just spent 3 hours fixing labels in our med dataset and found 17 errors where people wrote 'asprin' instead of 'aspirin'... and one guy labeled a tumor as 'normal' bc he was tired 😩 We need more coffee and better guidelines!!
Let me guess - this is just another corporate buzzword scam to make consultants rich. 'Systematic validation'? Please. The real issue is that Big Pharma and AI startups are using lazy annotators from Fiverr to cut costs. They don't care about patient safety - they care about hitting their KPIs and pitching to VCs. I've seen it. It's all smoke and mirrors. 🤡
Wow. Just... wow. You spent 1,200 words saying 'double-check your labels.' And yet, somehow, you still missed the fact that no one reads guidelines. Ever. 🙄
While the intent of this exposition is laudable, it lacks a rigorous epistemological framework for evaluating annotation fidelity. The reliance on heuristic manual inspection, rather than formalized inter-rater reliability metrics such as Fleiss’ Kappa or Cohen’s Weighted Kappa, undermines its scientific validity. Furthermore, the assertion that 'reading aloud' detects errors is anecdotally compelling but statistically unsound.
Bro this is so important I’m telling everyone I know. I used to think labeling was just grunt work, but after seeing how one wrong tag caused an AI to recommend the wrong dose for a diabetic patient (true story, happened at my cousin’s clinic), I get it now. 😅 It’s not just data - it’s someone’s life. I started doing peer reviews with my team and now we catch 90% of errors before they go live. It’s not hard, just gotta care. And yeah, read stuff out loud - it’s weird but it works! Also, if you’re not using version-controlled guidelines, you’re basically flying blind. Start small, trust me - your future self will hug you.
Let’s be real - this entire industry is built on a house of cards. People think AI is magic, but it’s just a mirror of the garbage we feed it. And now we’re pretending that if we just ‘add more examples’ or ‘train the annotators,’ we’ll magically fix systemic negligence? No. The truth is, healthcare institutions outsource labeling to the lowest bidder because they refuse to pay for quality. And then they wonder why their AI kills people. This isn’t a technical problem. It’s a moral failure. And until someone gets fired over a mislabeled drug, nothing will change. I’ve seen it. I’ve documented it. And I’m not backing down.
This made me tear up a little. I work in oncology data and sometimes I feel like no one sees how heavy this is. But you did. Thank you for saying it out loud. 💙
Okay but why are we still doing this manually?? I mean, I get it, humans are better at context - but come on. We have tools that can flag 90% of inconsistencies in 10 minutes. Why are we still making people read 500 clinical notes aloud?? This is 2025. We’re literally using medieval methods to fix digital problems. It’s like using a typewriter to code. I’m not saying ditch humans - I’m saying use tech to do the boring part so humans can focus on the hard decisions. 🙏
Just finished reviewing our allergy label set using the side-by-side method. Found 14 errors in 200 records. One was ‘penicillin’ labeled as ‘no allergy’ - the chart clearly said ‘anaphylaxis, penicillin’. We corrected it. The model’s false negative rate dropped from 18% to 7% in testing. This isn’t fluff. This is life-or-death work. And yes - we’re making a checklist. And yes - we’re doing it monthly. If you’re not doing this, you’re not just cutting corners. You’re gambling with lives. Don’t be that person.